NeRF 笔记
NeRF 笔记
写在前面
这原是我图形学课上论文阅读的一个作业,现放在自己博客里面,也当是我学习NeRF的一个小结。
NeRF
Abstract
NeRF提出了一种通过使用输入视图的稀疏集来优化底层连续体积场景函数,进而实现复杂场景的新视图合成的最先进的结果的方法。使用全连接(非卷积)深度网络,输入有五个维度(空间坐标$(x,y,z)$,视角方向$(\theta,\phi)$),输出是该空间位置的体积密度$\sigma$和视角相关的color。再通过传统的体渲染技术得到最后的像素值。通过比较生成图像和ground truth作为loss,来训练神经网络。
NeRF的意义是什么?
经典的图形学渲染流程中,我们是通过对输入的图像进行三维建模,再去进行自由视角的渲染。这就要求构建出非常高质量的三维模型才能渲染出精细的结果。但是很多情况下,三维模型的构建是比较困难的。但是NeRF基于深度学习的流程,通过对三维场景的神经表达,结合可微分渲染,可以实现端到端的训练。最终可以实现在任意视角下对模型的渲染。
NeRF的基本原理
NeRF的流程基本上可以用这幅图概括: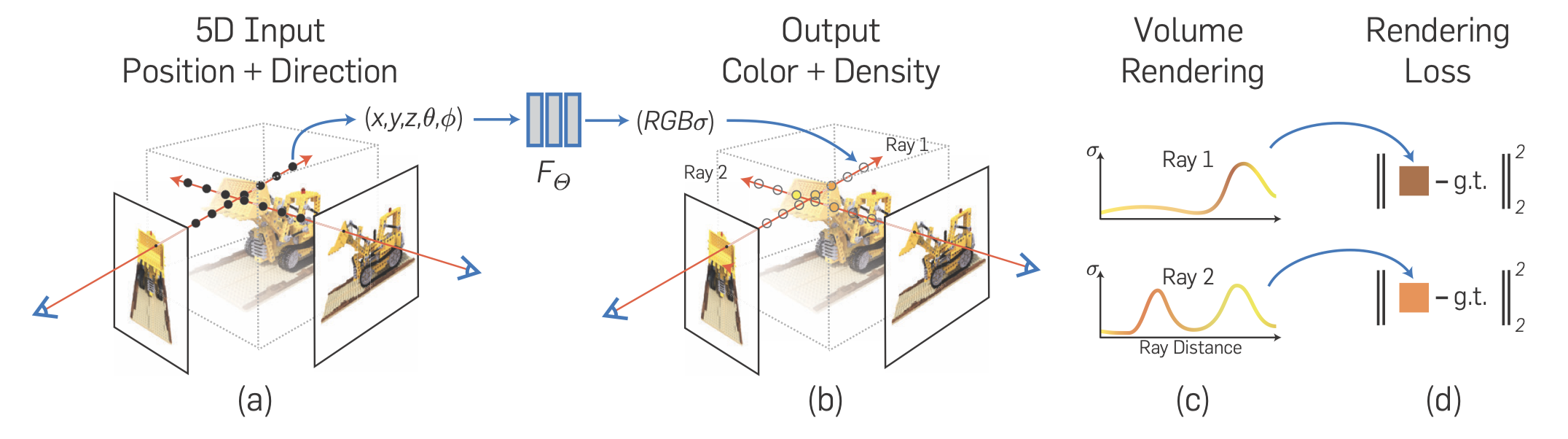
沿着相机光线,采样5D坐标合成图像 (位置和观看方向)
通过$r(t) = o + td$确定光线,沿着该光线得到采样点,$r_i=r(t_i)$
将这些输入MLP以产生颜色和体积密度
将采样点的三维坐标$(x, y, z)$和相机的视角$(\theta, \phi)$作为输入,得到$\sigma$和RGB值。
使用传统体渲染技术将这些值计算为最终的RGB值
$\begin{aligned} \hat{C}(\mathbf{r}) & =\sum_{i=1}^N T_i\left(1-\exp \left(-\sigma_i \delta_i\right)\right) \mathbf{c}_i, \\ T_i & =\exp \left(-\sum_{j=1}^{i-1} \sigma_j \delta_j\right)\end{aligned}$
通过最小化合成图像和真实图像之间的loss来优化我们的场景表示
$\mathcal{L}=\sum_{\mathbf{r} \in \mathcal{R}}|\hat{C}(\mathbf{r})-C(\mathbf{r})|_2^2$
NeRF的一些优化
位置编码
尽管神经网络是通用的函数近似器, 但作者发现, 让网络 $F \Theta$ 直接操作 $x y z \theta \varphi$ 输入坐标会导致渲染在表示颜色和几何形状方面的高频变化方面表现不佳。这与Rahaman最近的工作是一致的,这表明深度网络偏向于学习低频函数。他们还表明, 在将输入传递给网络之前, 使用高频函数将输入映射到更高维度的空间, 可以更好地拟合包含高频变化的数据。
View Dependence
这是基础图形学中的知识,高光依赖于视角的方向。
分层采样
利用第一次采样点预测的密度值确定第二次采样点的位置,可以减少计算的开销,同时也需要改变下体渲染公式
$\mathcal{L}=\sum_{\mathbf{r} \in \mathcal{R}}\left[\left|\hat{C}_c(\mathbf{r})-C(\mathbf{r})\right|_2^2+\left|\hat{C}_f(\mathbf{r})-C(\mathbf{r})\right|_2^2\right]$
以上1,2点的举例:
NeRF的局限性
- 最初时的NeRF计算效率比较低,训练时间长。目前,有一些模型的改善,包括instant-ngp(哈希编码),3D Gaussian Splatting(高斯核)。目前,3D Gaussian Splatting的效果很不错,对毛发的重建很逼真!!
- 无法进行泛化,一个神经网络只适用于一个模型。要是想再重建模型,只能重新训练。
- 无法重建动态的场景
HumanNeRF
Abstract
作者介绍了一种名为“HumanNeRF”的自由视点渲染方法。这种方法可以应用于单目摄像头拍摄的视频,例如YouTube上的视频,其中人物进行复杂的身体动作。其核心功能是允许在视频的任何一帧暂停,然后从任意新的摄像机视角渲染主体,甚至可以为那个特定的帧和身体姿势创建一个完整的360度摄像机路径。
这项任务特别具有挑战性,因为它需要合成从各种可能在输入视频中不存在的摄像机角度看到的身体的逼真细节,以及合成如衣服褶皱和面部外观等细微之处。
该方法通过优化人物在规范的T型姿势中的体积表示,以及与之配合的运动场,将估计的规范表示映射到视频的每一帧,通过后向扭曲实现。运动场被分解为骨骼的刚性运动和非刚性运动,这些运动由深度网络产生。
研究表明,与之前的工作相比,这种方法在性能上有显著的提升,并且在未受控制的捕捉场景中,展示了从单目视频中移动人物的自由视点渲染的引人入胜的例子。
HumanNeRF的基本原理
HumanNeRF的流程基本上可以用这幅图还有一个公式概括: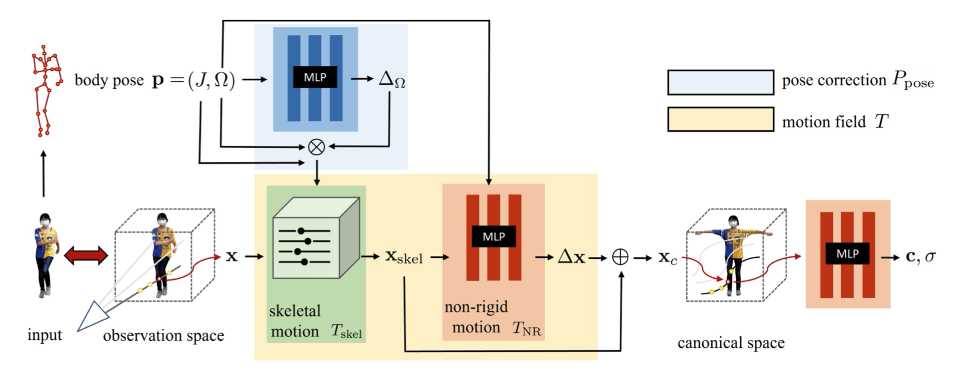
We represent a moving person with a canonical appearance volume $F_c$ warped to an observed pose to produce output appearance volume $F_o$ :
where $F_c: \mathbf{x} \rightarrow(\mathbf{c}, \sigma)$ maps position $\mathbf{x}$ to color $\mathbf{c}$ and density $\sigma$, and $T:\left(\mathbf{x}_o, \mathbf{p}\right) \rightarrow \mathbf{x}_c$ defines a motion field mapping points from observed space back to canonical space, guided by observed pose $\mathbf{p}=(J, \Omega)$, where $J$ includes $K$ standard 3D joint locations, and $\Omega=\left\{\boldsymbol{\omega}_i\right\}$ are local joint rotations represented as axis-angle vectors $\boldsymbol{\omega}_i$.
我先来讲下这个公式
$T:\left(\mathbf{x}_o, \mathbf{p}\right) \rightarrow \mathbf{x}_c$这个函数将observation space(观察空间)的点和当前估计的人体pose,映射回canonical space(标准空间)的点。函数$F_c$以标准空间的点作为输入,输出color和$\sigma$。可以看到,这里其实是和传统的NeRF不同的。正如我上面所说,传统的NeRF是有5维的输入,而HumanNeRF却少了$(\theta, \phi)$。这也正是HumanNeRF的一个缺陷,即只能考虑漫反射。
再来讲讲流程图
与NeRF一样,相机发出一条射线,再采样。但是作者这里思想非常巧妙。作者运用上面的公式,将观察空间中采样的点映射回标准空间中,从标准空间中采样。有几点好处:
- 姿态不变性:通过将观察空间中的点映射到标准空间,可以将人体的不同姿态统一到一个标准化的参考姿态。这样做有助于模型更好地学习和理解人体的三维结构,而不是专注于特定的姿态或视角。
- 数据一致性:在标准空间中处理数据可以确保不同图像或观察中的相同身体部位被一致地表示,这对于训练神经网络来说是非常重要的。这种一致性有助于网络更有效地学习和泛化。
- 简化学习任务:将复杂的人体动态映射到一个静态的、标准化的空间,可以简化学习任务。网络不需要同时处理人体的动态变化和外观变化,而是可以专注于从标准化的视角学习人体的外观。
- 更好的泛化能力:通过这种映射,模型可以更好地泛化到新的姿态和视角,因为它学习的是从标准化姿态到实际观察姿态的映射。这对于实际应用中的灵活性和鲁棒性是非常重要的。
- 高效的渲染:在标准空间中进行渲染计算可以提高效率,因为可以重用对于不同观察视角相同的计算结果,而不是针对每个新视角重新计算整个场景。
observation space的点映射到标准空间,作者将$T(x,p)$拆分成两部分:$T(\mathbf{x}, \mathbf{p})=T_{\text {skel }}(\mathbf{x}, \mathbf{p})+T_{\mathrm{NR}}\left(T_{\text {skel }}(\mathbf{x}, \mathbf{p}), \mathbf{p}\right)$。即骨骼和非骨骼两部分。骨骼的部分,正如其名,即为骨骼的映射。非骨骼部分,包括毛发、衣服,这些柔软的材料。
$T_{\text {skel }}(\mathbf{x}, \mathbf{p})=\sum_{i=1}^K w_o^i(\mathbf{x})\left(R_i \mathbf{x}+\mathbf{t}_i\right)$
刚体骨骼这里通过逆LBS实现,LBS具体实现可以参照games105(Lecture7)。逆即为从T-pose到observation pose。
$T_{\mathrm{NR}}(\mathbf{x}, \mathbf{p})=\operatorname{MLP}_{\theta_{\mathrm{NR}}}(\gamma(\mathbf{x}) ; \Omega)$
非骨骼这里通过MLP预测。
综上所述,HumanNeRF就是从单目摄像头出发,射出光线。在光线中采用,将采样点映射到标准空间中的点。再把标准空间的点输入神经网络,得到其$\sigma$和RGB。最后用体渲染的方式得到最后的像素值。
自己跑的一些结果



HumanNeRF的局限性
HumanNeRF对于novel pose不能泛化,其原因是HumanNeRF将Observation space 映射到 canonical space 过拟合了。MonoHuman修正了这个问题。
HumanNeRF可能会产生类似于米其林轮胎人的效果(应用新的人体pose):
MonoHuman
由于变形场是两个不同的多层感知器(MLP),并且依赖于帧或姿态,它们仍然面临过拟合问题。受上述工作的启发,我们设计了我们的共享双向变形模块,使用定义在规范空间中的相同运动权重进行前向和后向变形。
MonoHuman主要的实现,引入$\mathbf{L}_{\text {consis }}$:
In order to add the constraint that only related to the deformation field as a regularization, we use the intuition of consistency of forward and backward deformation, the consistent loss $\mathbf{L}_{\text {consis }}$ is computed as:
where $L_2$ means the $L_2$ distance calculation, and it only penalize the points whose $L_2$ distance is greater than threshold $\theta$ we set to avoid over regularization.
- 前向和后向变形的一致性直觉:这意味着变形应该是可逆的。例如,如果你首先应用一个变形,然后应用其逆变形,理论上你应该回到原始状态。
一致性损失 $\mathbf{L}_{\text {consis }}$:这是一个用来衡量变形前后一致性的损失函数。它的计算方式如下:
$L_{\text {consis }}=\left\{\begin{array}{ll}d & \text { if } d \geq \theta \\ 0 & \text { else }\end{array} d=L_2\left(\mathbf{x}_{\mathbf{o}}, D_f\left(D_b\left(\mathbf{x}_{\mathbf{o}}, \mathbf{p}\right), \mathbf{p}\right)\right)\right.$
其中 d 是通过以下方式计算的:
$d=L_2\left(\mathbf{x}_{\mathbf{o}}, D_f\left(D_b\left(\mathbf{x}_{\mathbf{o}}, \mathbf{p}\right), \mathbf{p}\right)\right)$
这里,$x_o$ 表示原始点,$D_f$ 和 $D_b$ 分别表示前向和后向变形函数,$p$ 表示相关参数。
- $L_2$距离计算:这是一种计算两点之间距离的方法。在这个上下文中,它用于计算变形前后点的距离。
- 阈值$\theta$:这是一个设定的阈值,用于决定何时对点进行惩罚。如果点的$L_2$距离大于这个阈值,它将被纳入损失计算中;如果小于这个阈值,则不会。这样做的目的是为了避免过度正则化,即只对那些变形效果不佳的点施加惩罚。
这是作者的一个结果,但是我运行的结果一般般,甚至感觉不如HumanNeRF
我的复现结果:
mesh:

重建结果:
